HTML Extract
processing.html-extract Processing v0.1.0 Extracts values from an HTML string with CSS selectors — text, inner HTML, or an attribute per rule, first match or all matches. Pair with HTTP Request to scrape a page (this node does not fetch).

Finding it in the library
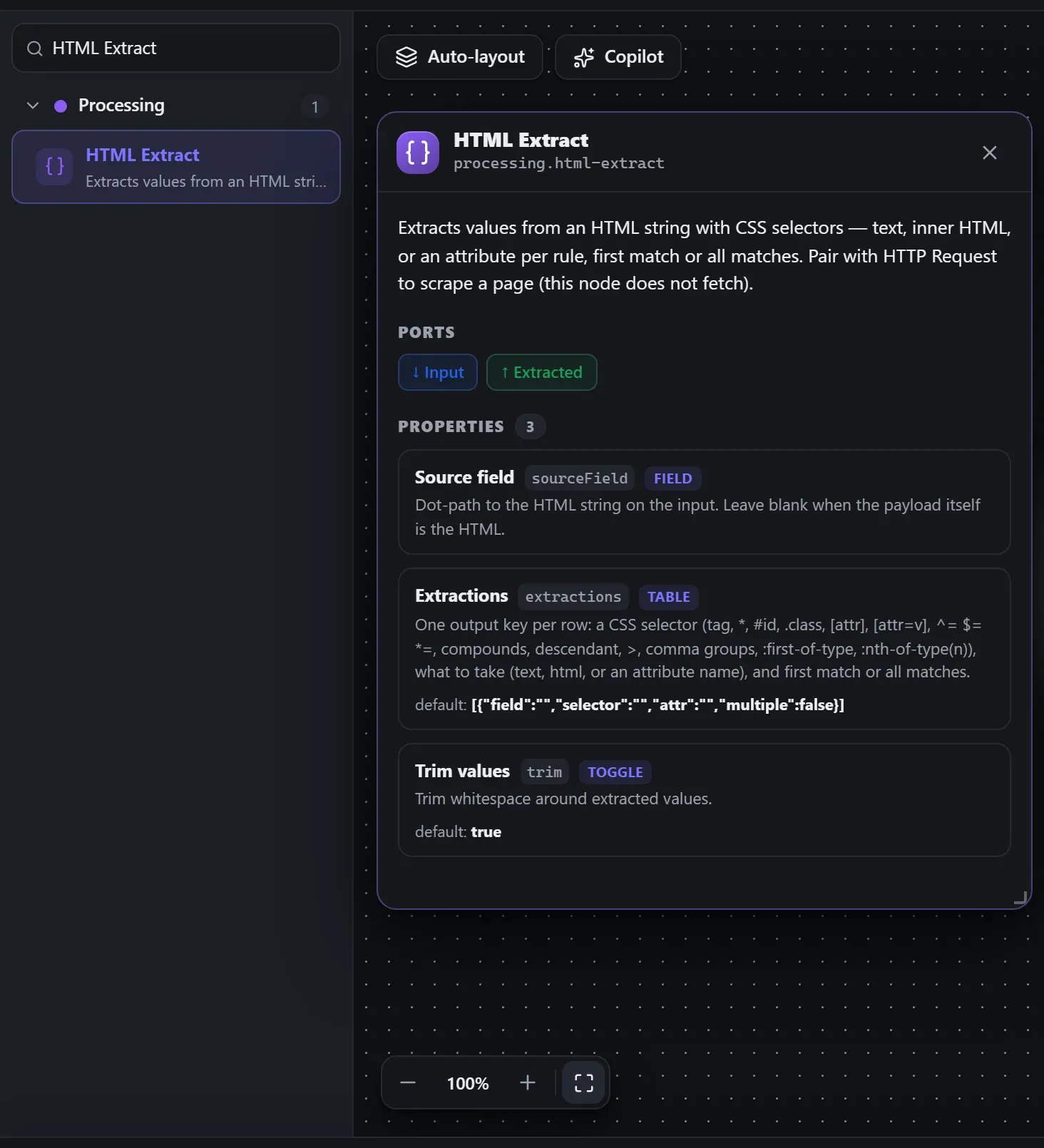
Search the builder's node library for HTML Extract (it lives under Processing). A single click opens the in-editor docs panel shown here — description, ports, and every property, without leaving the canvas. Double-click (or drag) to add it to the workflow.
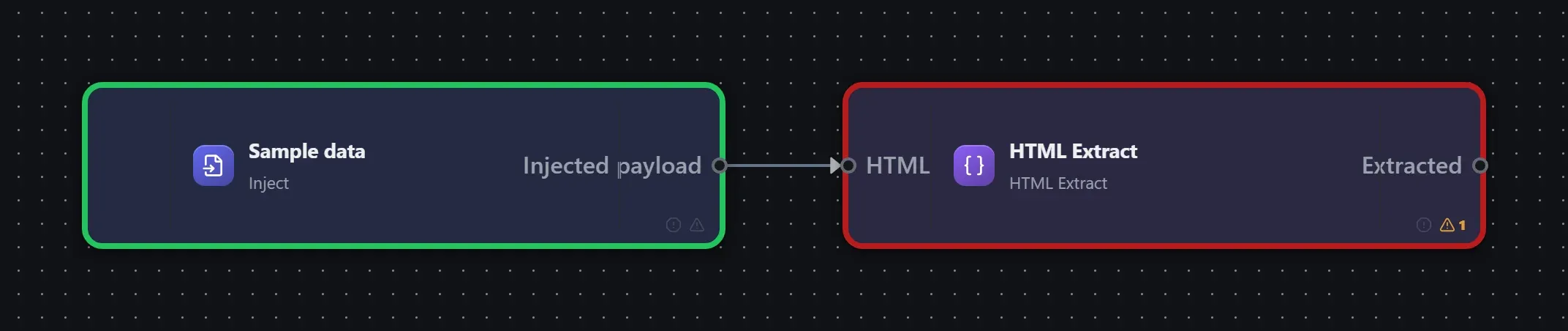
Wired up in the builder
HTML Extract in a real, runnable flow — captured live from the Studio editor, exactly as it looks on your canvas. This is the same workflow used for the example input & output below.
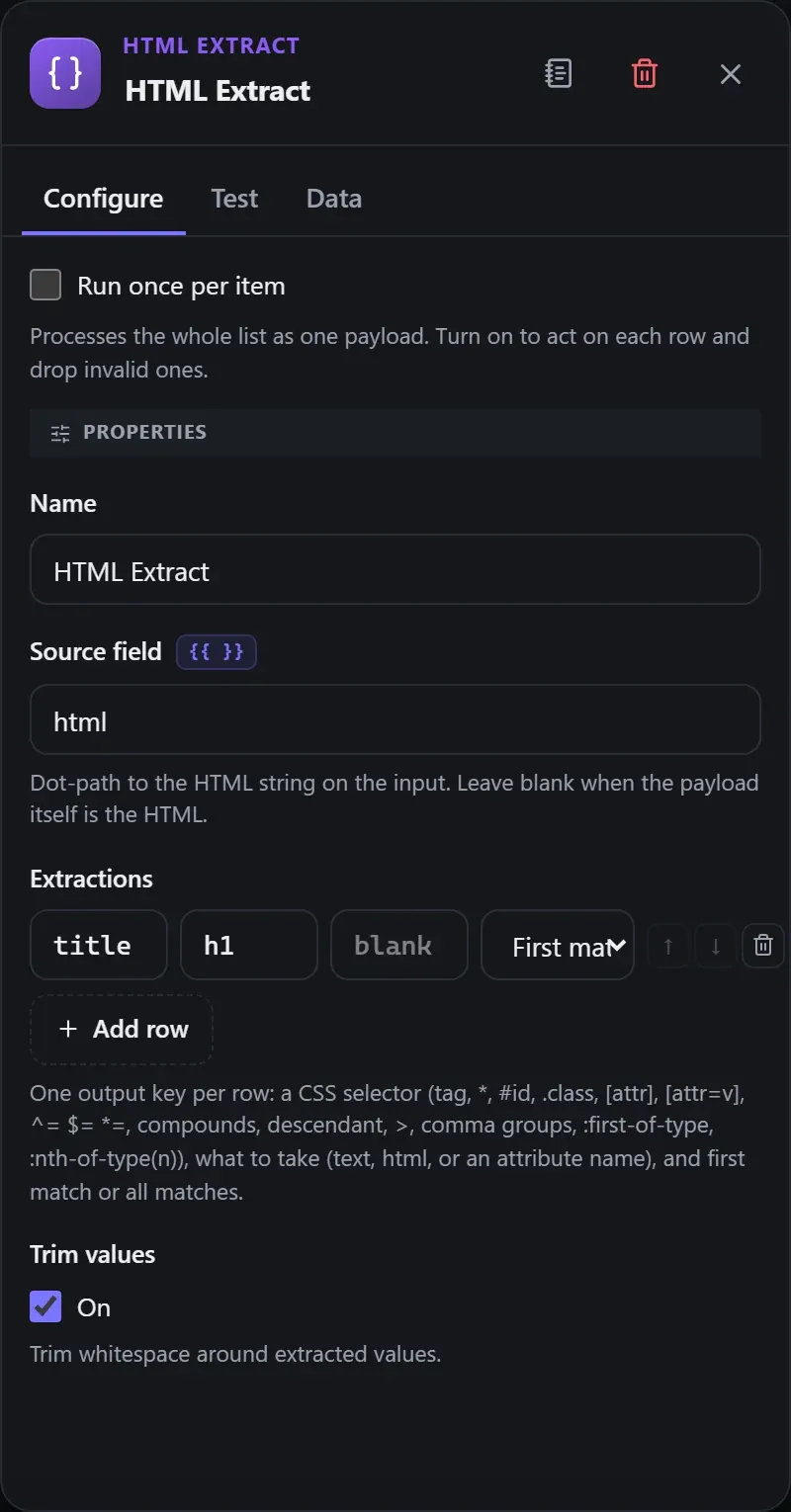
How it’s configured
The node’s Configure panel as it opens in the builder when you select the step — every setting laid out with real values. Click any field to edit it.
Ports
Ports are the node’s contract with its neighbours. In the editor a port label renders bold when wired and italic when optional; ◈ ports accept attachment carriers rather than data wires.
| Direction | Port | Label | What flows through it |
|---|---|---|---|
| Input | input | Input | |
| Output | output | Extracted |
How data flows through it
HTML Extract consumes the content of the incoming envelope — when it is fed directly by a trigger, the trigger’s wrapper is unwrapped at the node boundary so the node sees the actual data, not the metadata shell. Its output becomes the payload for the next node, while the envelope (trace ids, correlation, binary refs) rides along untouched. In the Runs view you always see the whole envelope for both sides of this node.
Expressions in the config
None of this node’s properties are string-typed, so {{ }} expressions
don’t apply here — JSON- and code-typed fields are always taken literally.
Build it with AI
Every node in this reference is reachable through Flowdrome’s
AI Copilot and the
MCP tools — say what you want, and the graph surgery
happens server-side. Node types resolve fuzzily, so the catalog label
(HTML Extract) works as well as the exact type id (processing.html-extract).
In the Copilot panel (or any connected AI):
add a html extract node after the triggerAs a step in a create_chain_workflow call:
{"type":"HTML Extract","config":{}}Raw MCP call — add this node to a workflow with add_node
curl -s -X POST http://localhost:48170/mcp -H "content-type: application/json" -d '{ "jsonrpc": "2.0", "id": "1", "method": "tools/call", "params": { "name": "add_node", "arguments": { "workflowId": "<id>", "type": "HTML Extract" } } }'Example input & output
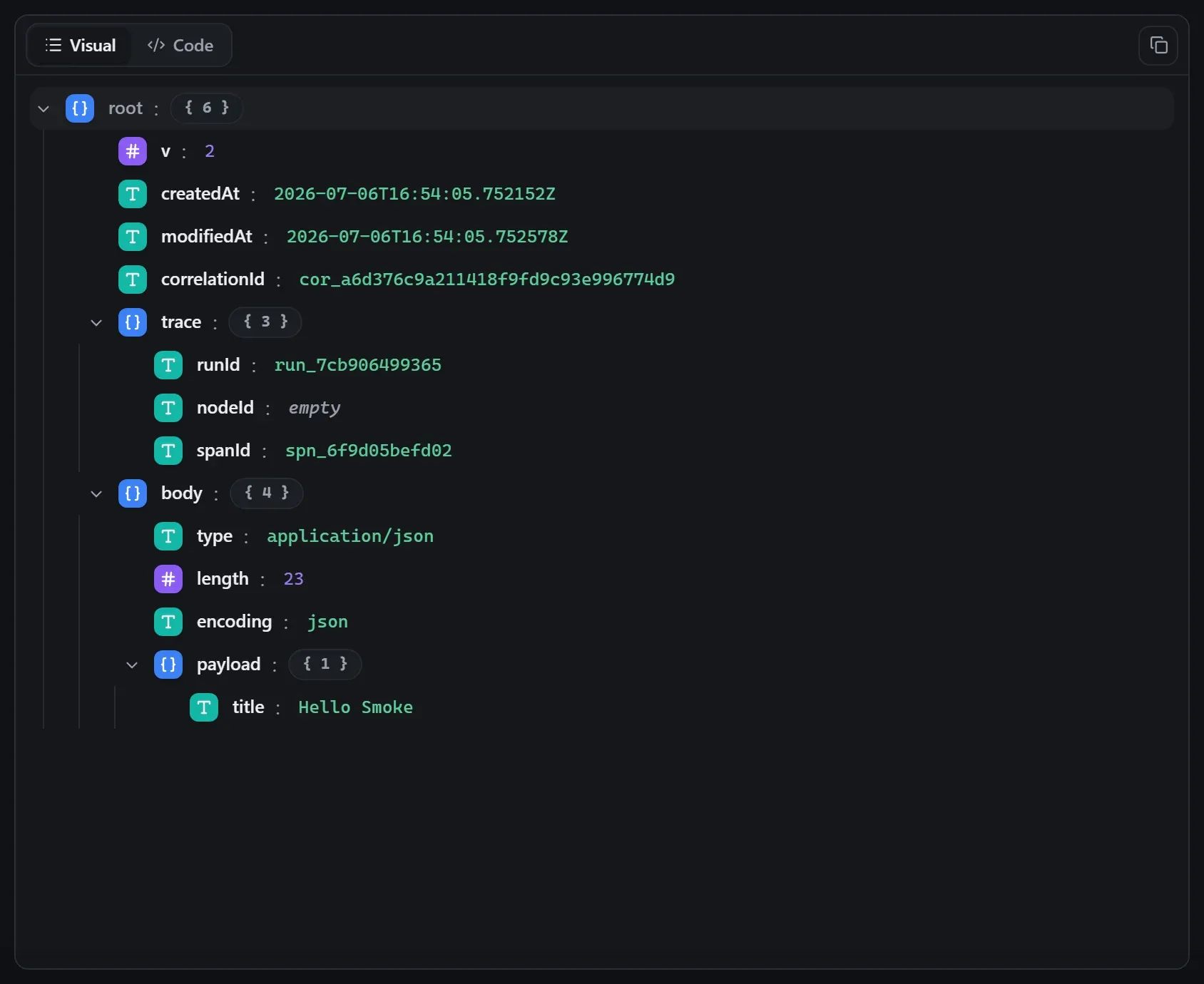
Captured from a real test run of the workflow above — this is what you see in the run data panel after pressing Test workflow.
Input — what the node received
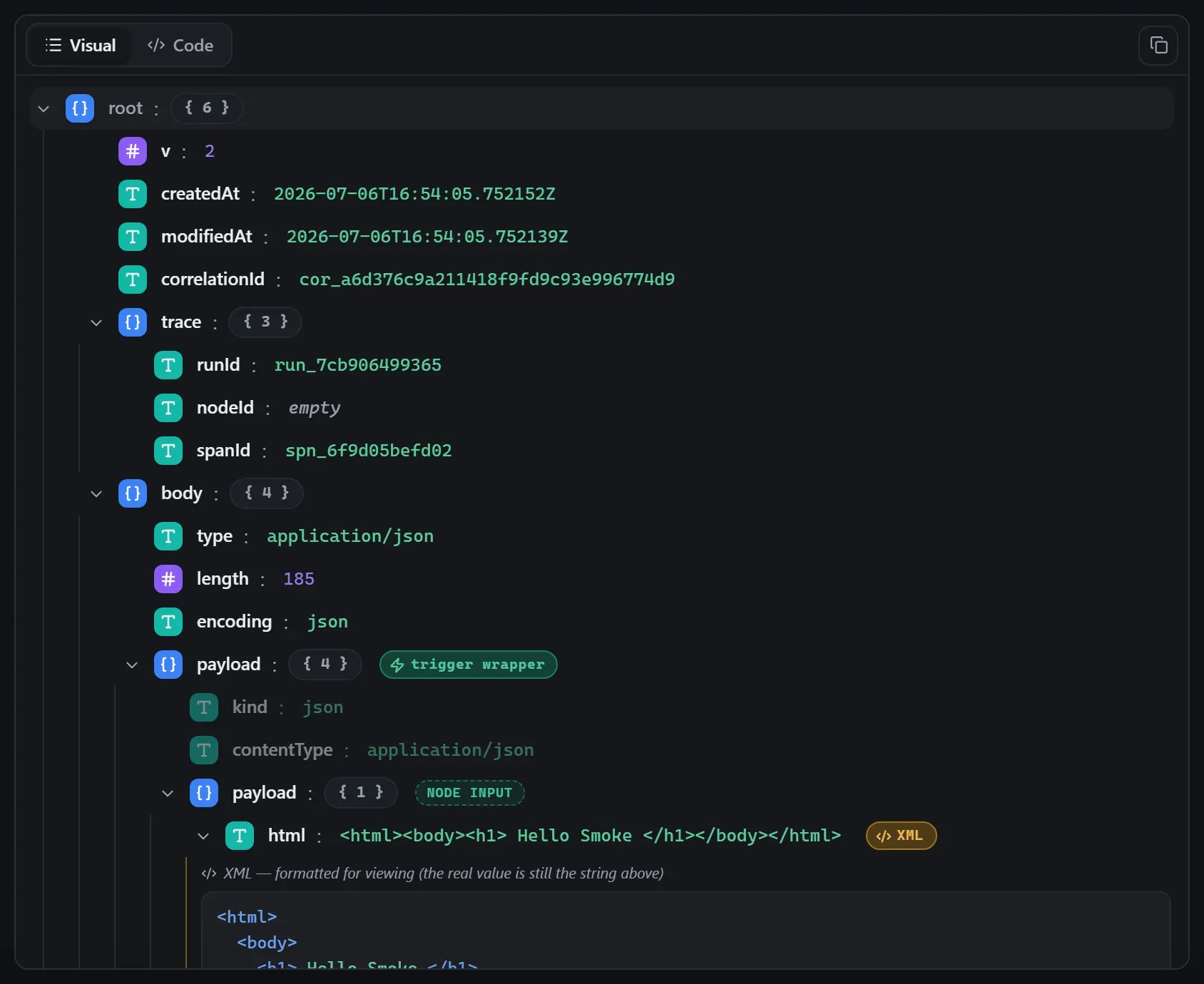
body.Output — what the node produced
Property reference
Every setting, with its type and default — the same fields shown configured in the panel above.
| Property | Type | Default | Description |
|---|---|---|---|
Source fieldsourceField | field | "" | Dot-path to the HTML string on the input. Leave blank when the payload itself is the HTML. |
Extractionsextractions | rows | [{"field":"","selector":"","attr":"","multiple":false}] | One output key per row: a CSS selector (tag, *, #id, .class, [attr], [attr=v], ^= $= *=, compounds, descendant, >, comma groups, :first-of-type, :nth-of-type(n)), what to take (text, html, or an attribute name), and first match or all matches. |
Trim valuestrim | boolean | true | Trim whitespace around extracted values. |
Related nodes
The rest of the Processing group — the same folder you’d scan in the editor’s library.
This page is generated from the node registry by gen-node-docs.mjs on every
site build — ports, properties, defaults and visibility rules cannot drift from the code.
The screenshots and example data are captured from a live Flowdrome by
npm run shots:nodes and npm run gen:examples.